全屋定制
转载AI算力芯片智能时代的普罗米修斯之火丨iNED观察
发布时间:2024-03-12 13:44:37 来源:华体汇平台官网入口春节之后,ChatGPT这一个名字在国内声名鹊起,它能够与用户进行流畅、自然、有趣的对话,展示了
“AI的‘iPhone时刻’已经到来”,全球最大的AI芯片制造商之一英伟达CEO在3月21日的GTC大会上这样说到,“各行各业正在应对可持续发展、生成式AI和数字化等强大的动态挑战,因此加速计算和AI的到来恰逢其时。”
为支撑OpenAI训练出ChatGPT,微软打造了一台由数万个A100GPU组成的AI超级计算机,此外,还有60多个数据中心、几十万张GPU支持ChatGPT的推理工作,预计GPT-4模型的商业化将需要超过3万枚A100芯片。可以说AI算力芯片是人工智能大模型的发动机,也是AI产业发展的重要基础。
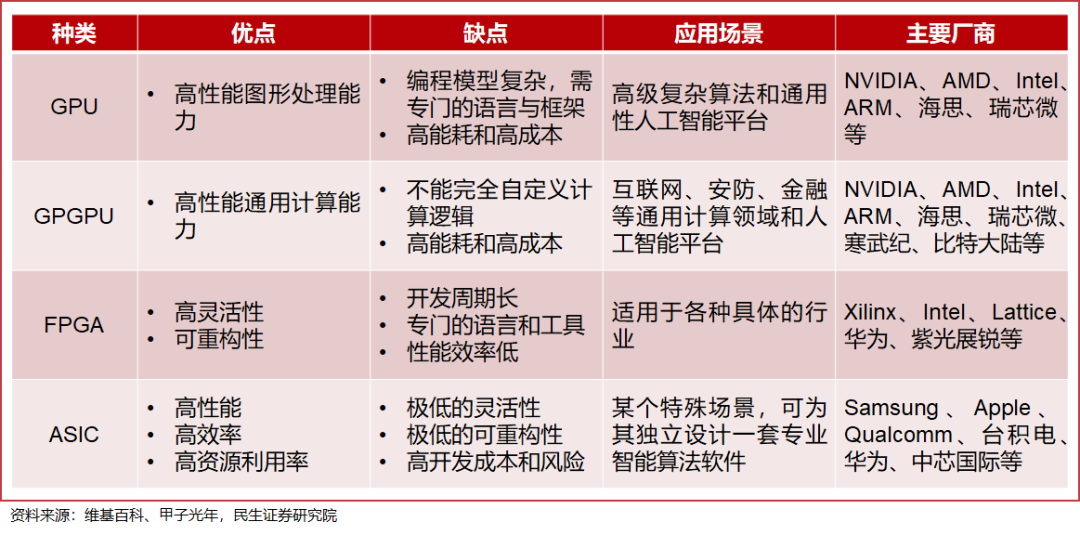
01AI算力芯片是何方神圣?AI算力芯片,也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块。从广义范畴上讲,面向AI计算应用并提供算力的芯片都被称作AI算力芯片,可满足AI算法的复杂度和多样性需求,具有高性能、低功耗、低延迟、高并行度等特点。其主要包括基于传统芯片架构的中央处理器CPU)、图形处理器(GPU)、现场可编程门阵列(FPGA)和专用集成电路ASIC),以及前沿的神经拟态芯片、类脑芯片、可重构通用AI芯片等,在云计算、数据中心、边缘计算、物联网智能手机智能汽车等领域具有广泛的应用场景。
GPU作为目前应用最广的AI芯片,是GPT训练模型中精度最高和算力最快的AI芯片,主要采用并行计算处理技术,堪称AI时代的算力核心。随着人工智能训练与推理需求的增加,还应运而生了——它可利用GPU的大量核心和高带宽内存,实现高度并行的数据处理,显著提高计算效率和性能;也可利用GPU的专用,如纹理单元、着色器等,实现特定功能的加速,解决传统CPU难以处理的问题,如科学计算、
根据机器学习算法步骤,人工智能有训练(training)和推理(inference)两个重要环节:
训练是指通过大量的标注数据来构建和优化一个复杂得神经网络模型,其能够适应特定的功能,如图像识别、语音识别、自然语言处理等。
推理是指利用训练好的模型,使用新数据推理出各种结论,如识别图像中的物体、转换语音为文本、生成自然语言回答等。
训练需要大量的数据和计算资源,以及一定的通用性,以便完成各种各样的学习任务;通常在云端或服务器上进行,需要高性能、高带宽、高精度的AI算力芯片。
推理需要快速将推理结果转化为行动,以及考虑单位能耗算力、时延、成本等综合指标。推理可以在云端或终端进行,需要低功耗、低延迟、低成本的AI算力芯片。

结合实际应用场景,根据芯片部署的位置,AI算力芯片又可分为云端训练、云端推理、边缘计算和终端四大类:
云端训练AI算力芯片用于构建和优化深度神经网络模型,具备高吞吐量、高精确率、可编程性、分布式、可扩展性、高内存与带宽等特点;
云端推理AI算力芯片用于利用训练好的神经网络模型进行预测和分析,对扩展性和带宽的要求较低,但具有低延时特点;
边缘计算AI算力芯片是在边缘设备上进行深度学习模型推理,实现模型的离线运行和本地处理的芯片,具有轻量化和可扩展特点;
终端AI算力芯片是实现模型的轻量化和优化,对数据进行本地处理和分析的芯片,可实现数据收集、环境感知、人机交互等功能,具有低功耗和协同性特点。
人工智能是数据、算法、算力的有机整合,正在从单一的技术工具演变为行业必不可少的生态系统,帮助人们解决复杂问题,改变人的生活和沟通方式。AI算力芯片作为底层算力设施的关键一环,在提高算法的运行速度和效率,降低成本和功耗等方面发挥举足轻重的作用。可以说,AI算力芯片是人工智能发展的基石,有望促进人工智能应用场景落地和万亿级数字经济产业变革,驱动智能化时代加速到来。在数字化转型、AIGC等浪潮下,AI算力芯片市场需求猛增。据TrendForce预测,2025年全球AI算力芯片市场规模有望达740亿美元;而据IDC数据,到2025年GPU仍将占据AI算力芯片80%的市场份额。可以预见,GPU在较长期时间内,依然是全球AI算力芯片厂商的角斗场。
据MordorIntelligence报告,目前,美国AI算力芯片市场主要玩家有英伟达、英特尔AMD,分为GPU和FPGA两大阵营。英伟达在GPU市场一家独大,市场份额高达90%,在训练和推理芯片领域遥遥领先其它厂商;英特尔与AMD则在CPU市场持续占据统治地位,双方各自收购了FPGA巨头Altera与Xilinx,旨在进入数据中心与嵌入式市场进行互博。
英伟达作为全球领先的芯片厂商,其GPU产品线丰富、产品性能顶尖、开发生态成熟,已经成为AI算力芯片的生态构建者和领跑者。其主流AI芯片分为四大类:面向数据中心的AI训练和推理芯片,如A100和H100;面向云端工作负载的AI推理芯片,如T4;面向边缘设备的AI加速芯片,如不同级别的Jetson系列SOC;面向专业图形和虚拟现实的AI芯片,如Quadro系列芯片等。其中,面向数据中心的AI训练和推理芯片最为行业所关注:

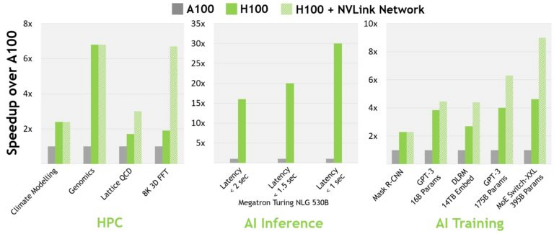
据英伟达公开数据表明,对于当今的主流AI和HPC机型,配备InfiniBand interconnect的H100的性能是A100的30倍。
据IDC报告,CPU+GPU的产品组合占中国AI服务器市场的91.9%,国内AI行业对GPU依赖性极高。
随着美国《2022芯片与科学法案》的出台以及针对中企进一步扩充“实体清单”名录等措施的落地,英伟达和AMD高端AI算力芯片被全面禁售给中国,敲响了高端AI算力芯片国产自主可控的警钟。但受限于工艺制程、EDA、IP核等技术封锁,国内AI芯片厂商的自主研制水平与国际一流水平还存在较大差距:
芯片制程工艺方面,全球3nm量产能力被三星和台积电两家企业垄断,英特尔与台积电在美工厂预计明年将实现4nm量产,而中国大陆目前还不具备4nm与7nm的制程工艺,由于台积电被限制技术转移,其只能在大陆投资落地28nm制程的生产线,大陆与世界领先水平整体差距在5-6年。
高端AI算力芯片方面,由于英伟达的A100与H100芯片向中国禁售,当前能获得的最佳替代品是专供中国市场的A800芯片(A100“版”),但其整体通信的带宽性能仅为A100的70%,数据传输速度受限、功耗更大,且市场高度紧缺。

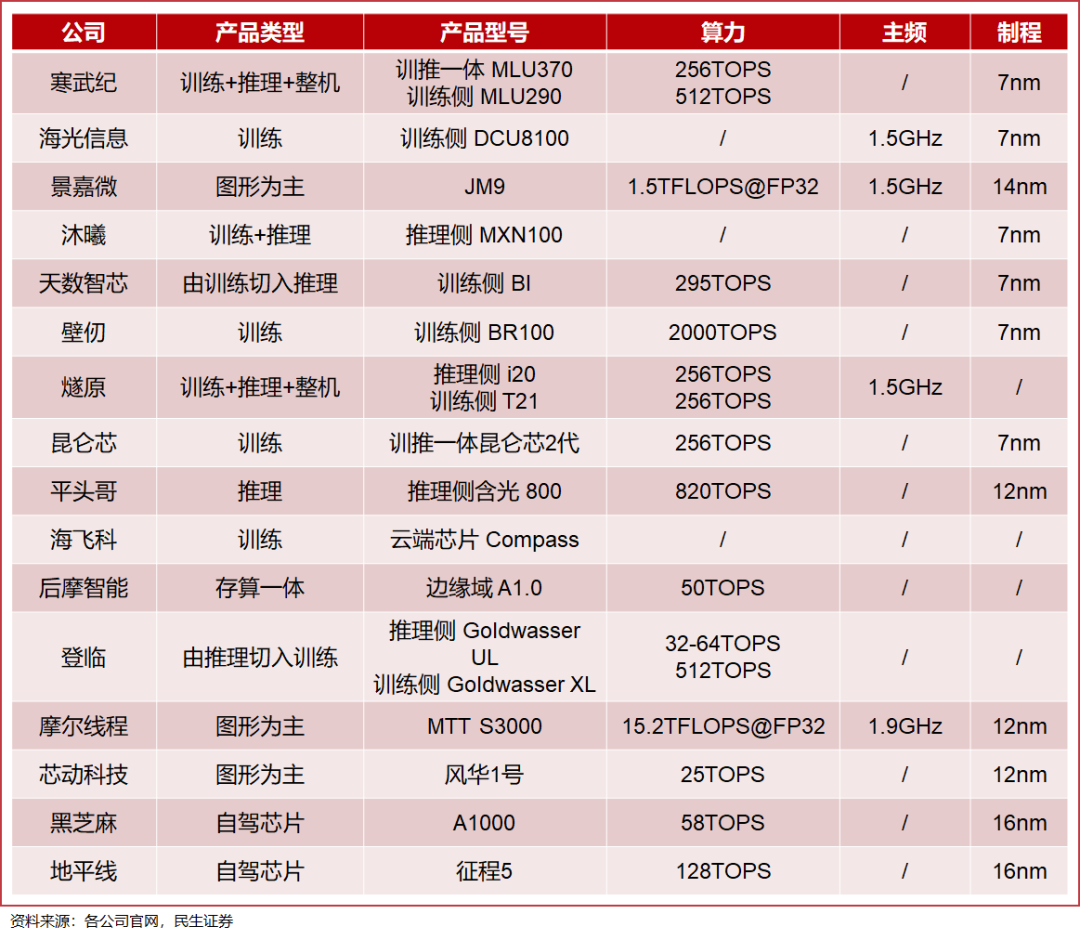
AI芯片厂商创始团队背景的中国AI芯片企业正加速涌现,国产AI算力芯片产品也不断实现创新突破。例如:深算1号的效能与NVIDIA P100相当,可运行AI大模型,苏州、成都等多地超算中心均搭载其CPU与计划于今年6月发布其GPU产品C100,公布的性能指标接近NVIDIA H100的水平;的BR100性能指标也对应NVIDIA H100,虽然其收到美国商务部打压需要重新设计产品,但其产品仍让人有所期待。
国家信息中心提出未来80%的场景都将基于人工智能,所占据的算力资源将主要由智算中心提供。继2020年成都超算中心落地后,2022年成都智算中心也成功投入使用,提供300P并在未来达到1000P的算力规模,成都成为全国除上海外仅有的投运超算和智算双中心的城市,也是全国首个专门出台算力产业专项政策的城市。
双中心可以近乎实时地存储、检索、处理和分析海量数据,提供业务性能授权单元支持,提供数据智能处理、AI模型快速开发部署等能力,同时提供高可靠的资源管理、用户管理、AI集群设备的运维和监控服务,成为本地乃至全国AI算力芯片产业高质量发展的重要基地和动力引擎,推动中国AI算力芯片走向全球领先地位。双中心为AI算力芯片带来的发展机遇:
为AI算力芯片的研发、测试、验证、优化等提供强大的计算支撑和数据服务,加速AI算力芯片的创新和突破;
为AI算力芯片的应用场景和需求提供丰富的案例和数据,推动AI算力芯片的产业化和商业化;
边缘计算AI算力芯片是在边缘设备上进行深度学习模型推理,实现模型的离线运行和本地处理的芯片,具有轻量化和可扩展特点;
为AI算力芯片的人才教育培训和交流提供平台和机会,促进AI算力芯片产业的人才聚集和创新氛围。
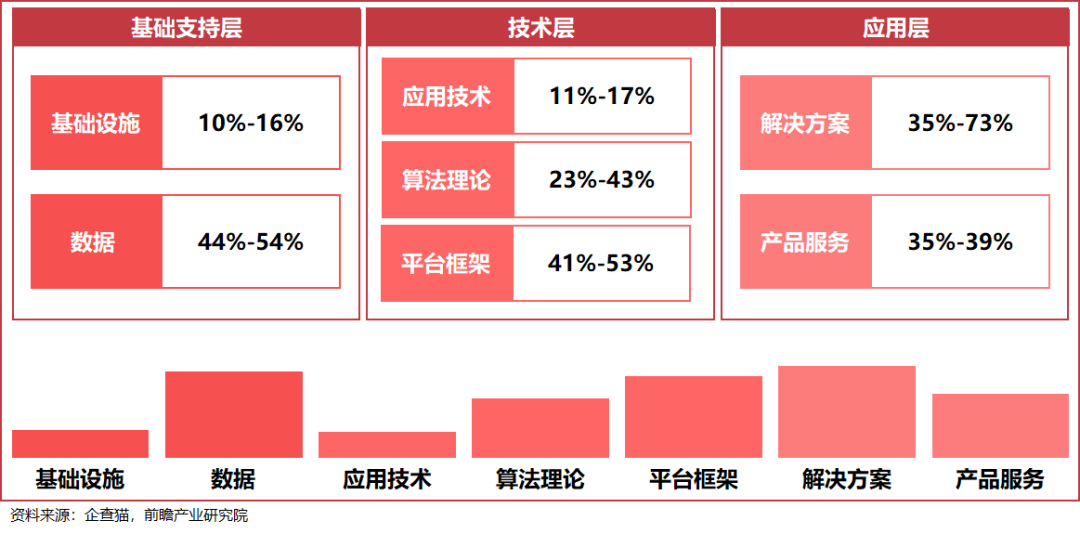
成都作为西部新一线年以来积极布局AI产业,形成了一批具有自主创造新兴事物的能力和市场竞争力的企业和团队。据统计,截至2022年9月,全市AI产业规模达469.2亿元,较2020年增长147%,核心产业规模位列全国第五,已基本形成完整的AI产业生态,覆盖基础层、技术层、应用层全产业链,特别是AI芯片、智能传感、数据和计算服务智能机器人等十大细致划分领域优势突出
其中,高新区拥有完整的电子信息产业链,集聚了全市75%的成长型AI核心企业。高新区在近日还发布了《成都高新区集成电路建圈强链三年攻坚计划(2023-2025)》,提出以模拟芯片为核心,以算力芯片、存储芯片及功率器件为重点,构建规模大、技术强、要素全的集成电路全产业链,加快“中国存储谷”建设,电子信息万亿级产业集群加快成型成势,本地算力芯片迎来新的发展机遇期。
据统计,2021年成都芯片产业总规模达1464亿元,同比增长20%,汇集英特尔、德州仪器、华为海思、成都海光、雷电微力、海威华芯等上下游企业200余家。其中,AI芯片产业规模约为184亿元(2020年),代表性企业有中科创达、启英泰伦、华天科技、北信源等,覆盖人工智能芯片设计、制造、封装、测试等全环节,囊括CPU、GPU、FPGA、ASIC等多种技术架构和云端、边缘、终端等多种应用场景。
启英泰伦,成都高新区瞪羚企业、省级专精特新中小企业、成都市新经济百家重点培育企业,成立于2015年,是集语音芯片、语音算法、应用方案、开发平台于一体的行业领导型语音解决方案供应商。成立至今,启英泰伦已推出多款智能语音芯片,涵盖离线语音芯片,语音AIoT芯片,语音蓝牙芯片,其中CI1006芯片被认定为国内首创,CI110X系列芯片被认定为国际先进。公司芯片产品现已大范围的应用于智慧家居家电、智慧养老、智慧穿戴、智慧医疗、智慧酒店、智慧安防、智慧教育、智慧汽车和机器人等领域,服务客户超过1000家。
SynSense时识科技成立于2017年,是一家起源于瑞士的类脑智能与应用解决方案提供商,公司秉承了苏黎世大学和苏黎世联邦理工学院20+年的类脑研发技术成果,专注于类脑智能的研究与开发,聚焦边缘计算应用场景,提供超低功耗、超低延时的全栈式类脑智能解决方案与服务,曾获评“全球唯一横跨感知与计算两界的类脑科技公司”“全球最需要我们来关注的100家半导体新创公司”“麻省理工科技评论50家聪明公司”。公司开发了多款低功耗、高性能、架构创新的类脑芯片产品,拥有全球首款“感算一体”动态视觉智能SoC Speck、XYLO 类脑处理器、DYNAP-CNN神经形态处理器及完整工具链,可运用于智能家居人机交互、机器人、无人驾驶、可穿戴设备、智能安防、物联网等。
虽然国内寒武纪、百度、燧原、华为等一众企业的技术水平及产品性能都落后于英伟达一代或两代,但AI算力芯片作为数字中国的算力基础,国产突破势在必行。面对摩尔定律边际效用递减的困境,ASIC芯片的弱通用性难以应对下游算法的快速演化,GPGPU又难解高功耗与低算力利用率问题,业界正翘首以盼新架构、新工艺、新材料、新封装,以进一步突破算力天花板。谁能率先填补大模型算力需求的缺口,谁就有机会抢占新一轮AI芯片抢位赛的前排。
其关键在于探寻“弯道超车”路径,特别是存算一体、超异构、Chiplet(芯粒)、3D封装等新兴技术路线的提出,跳出了冯·诺依曼架构体系,理论上拥有高能效比优势,兼顾更强通用性与更超高的性价比,算力发展空间巨大,有望弥补中国企业与英伟达在硬件技术和软件生态方面的差距,摆脱国内对先进制程技术的依赖。例如:存算一体芯片对工艺技术要求较低,在28nm工艺上实现的算力和能效就能比肩甚至超过传统架构芯片在7nm工艺上的表现。
从超异构来看,国内CPU有广受欢迎的开源RISC-V架构,GPGPU有新兴的开源架构“青花瓷”平台,存算一体也有亿铸科技等厂商在大力投入研发。随着工艺不断迭代,国内企业“超车”速度会慢慢的快,优势会慢慢的明显。
突破技术瓶颈并非一日之事,必须脚踏实地,加大资源持续投入,有耐心有定力,久久为功,才能踏上发展的“快车道”;我们大家都希望有更多的本土企业走到换道前行的赛道上,为破解国内AI大算力困局探寻属于中国AI芯片产业的发展道路。
·40张图表解析中国“芯”势力:2021年中国AI芯片发展简报及典型厂商案例——甲子光年
·2022年成都市AI行业产业链现状及发展前途分析——前瞻产业研究院
·迈向巅峰之路——中国成长型AI企业研究报告——英特尔,德勤,深圳市人工智能行业协会
有8G的显存,能处理复杂的算法,提高挖掘稳定性。iBeLink ks max10.5T的超大特点是它的高效节能,它采用了先进的“存
设计师,拥有世界领先的自主开发稀有算法,作为双重稀有算法的发明者,公司的目标是制造世界新一代人工
(Prometheus)是一个SoundCloud公司开源的监控系统。当年,由于SoundCloud公司生产了太多的服务,传统的监控已经没办法满足监控需求,于是他们在2012年决定着手开发
:接近完美的监控系统 /
增强场景的 RISC-V 全栈软硬件平台。 该平台将 RISC-V 扩展性的新型 Vector、Matrix 及第三方硬件进行
大模型已经孵化;繁衍过程将突飞猛进,ChatGPT已经上线。 世界首富马斯克认为
(三) /
(二) /
休斯,推出一款价格较低的互动平板ActivPanel LX,为客户提供更优越的易用性及灵活性功能,同时保证产品的质量和常规使用的寿命。随着这一新产品的推出,
休斯已做足准备以满足教育技术市场细分领域一直增长的需求。 ActivPane
迅为RK3568以及RK3588开发板内置独立NPU,RK3588运算能力高达6TOPS,RK3568运算能力高达16TOPS
基于先楫HPM5300 RISC-V内核MCU的HPM5361EVK开发板测评效果(二)
栅极环路电感对IGBT和EliteSiC Power功率模块开关特性的影响简析